We have all been there - that dreaded family gathering where some relative walks up to you and starts complaining how slow his computer has become and that he needs a new one.
In the old days this was a serious problem. They really meant what they said: They need a new computer and you are the only one to make that happen. Go buy and setup a new rig, then spend at least an afternoon installing all kinds of things so the new computer works just like the old one, but moderately faster.
Thank god we got SSDs now, so I can make any computer ten times faster without having to replace the whole damn thing. And there is even a trick how you can migrate from the old hard-drive to the new SSD without you having to reinstall Windows or anything.
The trick is to clone the existing drive using a nifty tool called GParted. Here is how it's done:
(It's kind of a long post, but believe me you can do this in less than 20-30 minutes)
Prerequisites
Buy an SSD
Don't waste money on anything fancy. Any SSD will make a PC fly compared to a mechanical drive. So just get a decent drive with the capacity you feel is required and be done with it. (I just got a 240GB drive for 150€ and score a 7.9 in Windows Performance Measurements)
Backup the old Data
As always with disk operations, they might result in lost data if something goes wrong, so please back up any relevant data on the drive you want to copy.
Step 1- Prepare a GParted-Live USB-Key
Get an USB thumb-drive and install GParted-Live using the excellent Pendrive Linux installer. That's simple:
After that it's as simple as selecting GParted in the dialog, pointing it to the GParted iso file and selecting the USB drive letter you want to install your GParted image to.
Step 2 - Delete some data from the original drive
Usually the new SSD will have less capacity than the existing drive (you're usually going from 500GB to 240 or something) so you have to make sure the old data fits on the new drive.
Uninstall applications, move data - make sure the used space on your old drive is less than your SSD capacity before proceeding.
Step 3 - Unplug all unnecessary drives
You're going to do some pretty low-level disk operations and any chance you can mess up drive letters is a recipe for desaster. So I like to just disconnect all drives except for the old drive that contains Windows.
Just to make it harder to accidentally screw up.
Step 4 - Install the SSD into the computer
Step 5 - Plug in the USB-Key with GParted and boot it
You will soon be greeted by GParted running in a rather hideous Linux GUI.
Step 6 - Shrink the old disk (optional)
If you are trying to fit a bigger old drive onto the new SSD you have to shrink the old partition to a size that's smaller then the new SSD. That's important otherwise you'll screw up the partition table when copying the disks.
Thankfully GParted can do that for almost any file system, even with NTFS. Just select the old partition and shrink it.
All partitions together should be less than the new disk capacity - the rest should be unpartitioned space at the end of the disk.
Step 7 - Clone the disk
What you need next is to use GParted to find out the drive paths of your old drive and your new one.
This can usually be deduced from their respective sizes, but also the new one should not contain any partitions yet.
Just click the drive path to the top right and you will see a listing of all connected hard drives with their linux mount point (/dev/sda is the first one and /dev/sdb the second etc..)
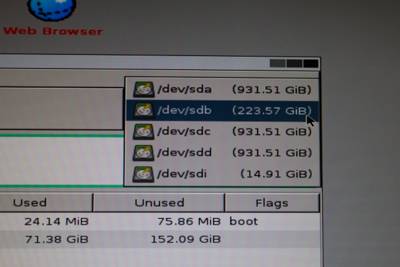
Once you know the respective drive names, open up the Terminal and run the dd command like this:
dd if=/dev/sda of=/dev/sdb bs=100M status=progress
if should point to the old disk and of is the new disk. (if is short for InputFile and of for OutputFile)
Make sure that you get this absolutely right, otherwise you end up cloning the empty disk onto the full disk!
Once done just restart the computer and boot once again into GParted.
Step 8 - Grow the new disk.
You are almost done, but you usually have a bit of unused disk space on the SSD left - so you GParted to grow the partition to fill the whole space.
Step 9 - Format the old disk
If you are feeling brave you can do this right away, I like to unplug the old boot disk and reboot from the SSD to make sure everything is working.
After you are sure the new SSD boots into Windows, plug the old hard drive back in and boot into GParted again.
You should now just remove all partitions from the old disk to free up the space and make sure you don't accidentally boot to the wrong Windows.
(Don't worry about new partitions, you can do that from the Windows disk manager).
Step 10 - Reboot into Windows
Done! Unplug the GParted USB-Key and boot the PC. You will be greeted by checkdisk, but once done you should see a very speedy boot into the old desktop.
Now you can use the disk-management tool inside Windows to create a partition on the old disk and you are done.
Everything works as before, you just saved yourself countless hours of reinstalling every spyware/malware the relative has accumulated over the last few years.