During the last few months I have been the technical architect behind the development of a new platform for tourism in Carinthia. While I have already discussed some of the inner workings of the project during that time, I thought it might be interesting to let you in on a deeper look at the application architecture behind the site: www.kaernten.at.
Quick facts:
The site is built using ASP.NET MVC (since Beta 3) being hosted by IIS6 on a MSSQL 2005 database.
The whole thing is glued together by Castle Windsor and DynamicProxy2 while tests are all run through xUnit and Rhino.Mocks. The error reporting is done through ELMAH.
General Architecture
There are three layers to the application:

The Web tier was the actual ASP.NET MVC Site and this was the part I was least involved in. The Controllers use the Services layer to retrieve relevant information and then passes it on to the View.
I knew from previous projects that the web tier is the first place that is going to get torn apart by weird customer requests and other very ui-driven changes, so the general goal of the services layer wasn’t only to present data to the web, but to provide services to manipulate that data for presentation. So the Services layer is mostly about filtering/sorting/querying data from the database, since there is no common logic to the madness of presentation requirements.
The database tier is actually split across two tiers, the Sql tier and the Proxy tier. (I’ll cover the Proxy in a future post in more detail.) Most notable the whole database retrieval is done through Linq to Sql.
Also everything in the system is dependency injected, there is not one call to new() anywhere in the system, except for the construction of data objects (that in my design aren’t allowed to have services on them).
Query logic
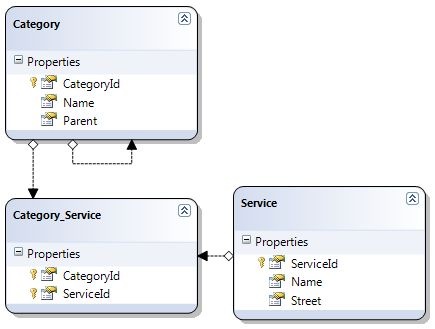
The whole site is based on the concept of When youre visiting? What are you interested in? And Where would that be?
So, there is not a typical tree of categories with articles to browse through, but rather is the whole content of the site the result of all articles that match your criteria. Therefore every article in the system has a list of tags it’s connected to (when and what both are just tags).
Now, one of the main challenges for all of the team (involving the customer) was to really define that query logic, and we changed it about 10 times during development, and I’m sure it will change even more in the future.
So, although it might have been possible to do all querying/sorting/filtering with Sql, the Sql code became utterly unreadable and sometimes involved n subselects.
I gave up on the Sql pretty early on since it was just too un-maintainable and felt too restraining.
My solution to this was to load all articles into memory and filter/sort them from there. This then enabled me to easily implement queries like this one:
All articles that are tagged a,b,c AND at least one of d,e,f (or more formally: (a && b && c) && (d || e || f))
And that’s about it for the general picture right now. I’m planning on posting more on the technology behind www.kaernten.at over the next couple of days.